GANs and DCGANs
• Snowkylin
![]()
生成对抗网络(GANs)与深度卷积生成对抗网络(DCGANs)
生成对抗网络(Generative Adversarial Networks, GANs)是无监督学习的一个比较新的分支,由Ian Goodfellow等于2014年提出,其优秀的性能很快获得了学界的普遍关注。
该模型包含两个神经网络,一个是生成式模型,一个是判别式模型。生成式模型类似于一个“仿制者”,需要生成能尽量不被判别式模型识破的假样本;判别式模型则类似于“警察”,需要将假的样本探测出来。这两者之间的博弈和竞争使得两个模型的能力都同时增强,直到生成式模型生成的假样本无法和真实样本区分为止。
生成对抗网络(GANs)
本部分对该模型进行更细致的描述。首先,我们考虑一个简单的分布$ p_z $(例如,-1到1之间的均匀分布)。我们把“从$ p_z $这个分布中取样一个值$ z $”的操作定义为$ z \sim p_z $。
然后,我们定义一个函数(生成式模型)$ G(z) $,将我们从$ p_z $取样得到的$ z $映射为一个“假样本”。这里的$ G(z) $往往使用深度神经网络实现。
有了$ G(z) $之后,我们将$ G(z) $(此处$ z \sim p_z $)看做是在从一个分布中取样,并把这个分布记做$ p_g $。同时,我们将原始样本数据的(未知)分布定义为$ p_{data} $。最终,我们希望$ p_g = p_{data} $。
现在,我们考虑另一个函数(判别式模型)$ D(x) $,将某个数据样本作为输入,并给出“这个样本是取样自$ p_{data} $”的概率。如果这个概率接近于1,说明该样本很大可能是取自原始样本数据的分布$ p_{data} $。若接近于0,则说明该样本为“假样本”。这里的$ D(z) $也往往使用深度神经网络实现。
于是,我们对于判别式模型$ D $的训练目标是:
- 对于$x \sim p_{data}$,$D(x)$都尽量大。可以表示为\(\max_D \mathbb{E}_{x \sim p_{data}} \log D(x)\);
- 对于$x \not\sim p_{data}$(或者说,$x \sim p_g$),$D(x)$尽量小。可以表示为\(\min_D \mathbb{E}_{x \sim p_g} \log D(x) \Leftrightarrow \min_D \mathbb{E}_{x \sim p_z} \log D(G(x)) \Leftrightarrow \max_D \mathbb{E}_{x \sim p_g} \log(1 - D(G(x)))\)(作为概率值,$D(x)$的取值范围在0至1)。
由此,对于$ D(x) $,我们需要:
\[\begin{equation*} \max_D \mathbb{E}_{x \sim p_{data}} \log D(x) + \mathbb{E}_{x \sim p_g} \log(1 - D(G(x))) \label{eq-D} \end{equation*}\]而对于生成式模型$ G(x) $,我们的训练目标是让$ x \sim p_g $时$ D(G(x)) $都尽量大。可以表示为\(\max_G \mathbb{E}_{x \sim p_g} \log D(x) \Leftrightarrow \max_G \mathbb{E}_{x \sim p_z} \log D(G(x)) \Leftrightarrow \min_G \mathbb{E}_{x \sim p_g} \log(1 - D(G(x)))\)。</span>
由此,对于$ G(x) $,我们需要:
\[\begin{equation*} \min_G \mathbb{E}_{x \sim p_g} \log(1 - D(G(x))) \label{eq-G} \end{equation*}\]结合上面两式,我们可以得到下面统一的表达式:
\[\begin{equation*} \min_G \max_D \mathbb{E}_{x \sim p_{data}} \log D(x) + \mathbb{E}_{x \sim p_g} \log(1 - D(G(x))) \label{eq-GAN} \end{equation*}\]具体算法如下:

其中,$ \theta_d $是判别式模型$ D(x) $的参数,$ \theta_g $是生成式模型$ G(z) $的参数。$ k $是一个超参数,控制更新多少次判别式模型后才更新一次生成式模型。
深度卷积生成对抗网络(DCGANs)
深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Networks, DCGANs)由Alec Radford等于2015年提出。在了解GANs的架构后,我们可以较为容易地了解DCGAN的原理。
在DCGAN中,生成式模型$ G(z) $使用一个比较特殊的深度卷积网络来实现,如下图所示。
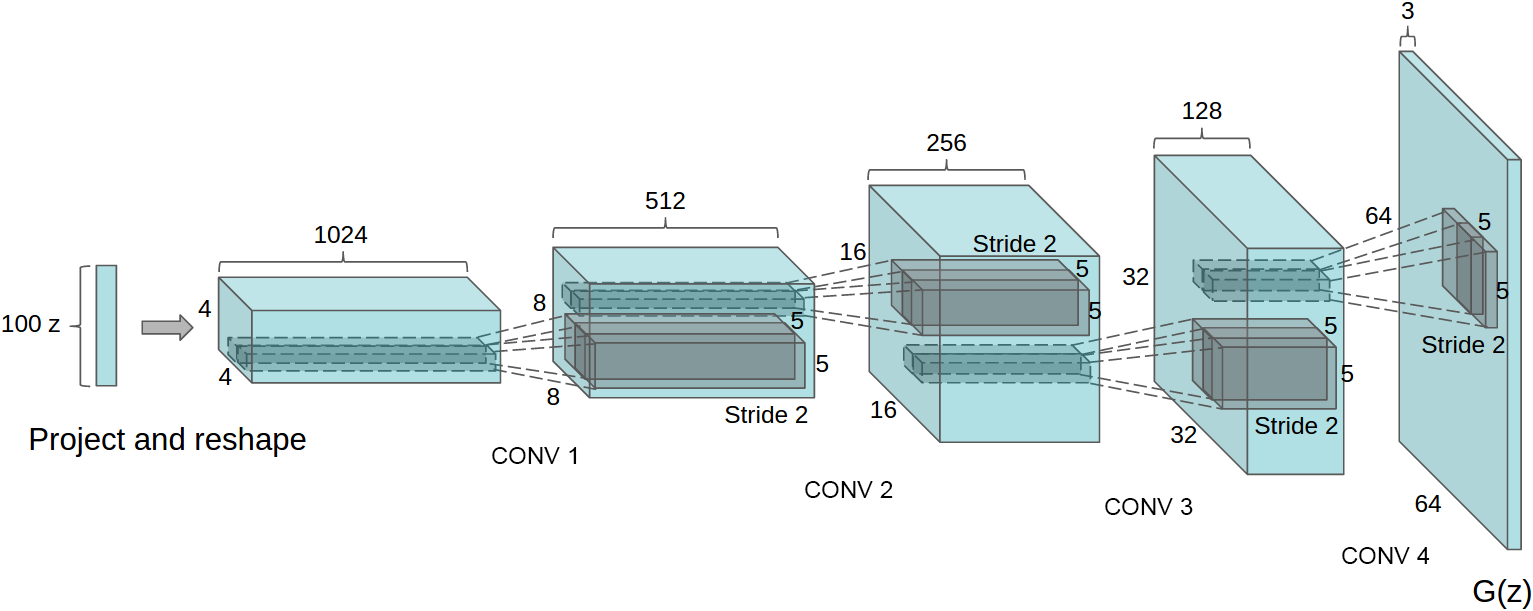
DCGAN中生成式模型$ G(x) $的示意图。
而判别式模型$ D(x) $则仍是一个传统的深度卷积网络,如下图所示。
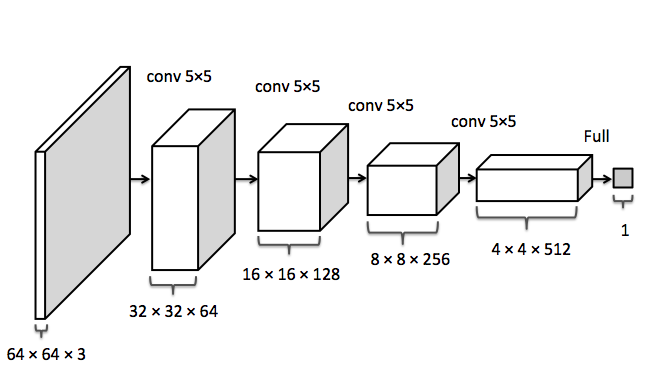
DCGAN中判别式模型$ D(x) $的示意图。
从图中可以看出,DCGAN的生成式模型$ G(z) $中出现了上采样(upsampling)。卷积神经网络的下采样很好理解,加入polling层即可,然而这里的上采样要如何实现呢?这里,DCGAN通过“微步幅卷积”(fractionally-strided convolution)进行上采样。假设有一个$ 3 \times 3 $的输入,希望输出的尺寸比这要大,那么可以把这个$ 3 \times 3 $的输入通过在像素之间插入0的方式来进行扩展,如下图所示。当扩展到$ 7 \times 7 $的尺寸后,再进行卷积,就可以得到尺寸比原来大的输出。
通过“微步幅卷积”(fractionally-strided convolution)进行上采样的示意图。
参考
- Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems, pages 2672–2680, 2014.
- Image Completion with Deep Learning in TensorFlow http://bamos.github.io/2016/08/09/deep-completion
- Convolution arithmetic https://github.com/vdumoulin/conv_arithmetic